
Fastbook Lesson 2
Questions
1. Provide an example of where the bear classification model might work poorly in production, due to structural or style differences in the training data.
The bear classfication model will work poorly in real life conditions, where we would be dealing with video instead of images, the input of the cameras might be of very low resolution, nighttime images, we have to ensure there is no processing latency, bears might not be properly positioned in from of these cameras.
2. Where do text models currently have a major deficiency?
Text models have a major deficiency in conversation.
3. What are possible negative societal implications of text generation models?
The negative implication of text generation is the fact that these models produce really persuasive articles but the verfication of their content can't be done so easily.
4. In situations where a model might make mistakes, and those mistakes could be harmful, what is a good alternative to automating a process?
5. What kind of tabular data is deep learning particularly good at?
Deep learning is good at tabular data with high cardinality i.e. data that has a lot of discreet values like zip codes or product ids.
6. What's a key downside of directly using a deep learning model for recommendation systems?
Deep learning models are usually used to create predictions which don't translate into great reccomendations. Like Amazon could recommend buying books of the same author just because those products are related or some people bought it with that book using collborative filtering, but this doesn't necessarily mean that it is a good recommendation. If you compare this with a human bookseller who might recommend similar books of the same genre or writing style.
7. What are the steps of the Drivetrain Approach?
8. How do the steps of the Drivetrain Approach map to a recommendation system?
The objective in a recommendation system model would be to give users say for music, not music with the same artist but music that sounds alike to the one's they are listening to and might be a little obscure to find. Here we can control what is recommended whether we want to follow a similar genre pattern or music that sounds the same. Then we can collect data on whether the user liked the playlist we curated for them by the songs they liked in them or put in their own playlists. Depending on tha we create a model.
9. Create an image recognition model using data you curate, and deploy it on the web.
The first part I am done with, I just can't deploy it on the web. My project: Sudoku Solver10. What is DataLoaders?
A DataLoader grabs 64 images at once and loads it into one batch so that this batch of images are all passed to the GPU at one go, which increases the speed. This batch size is set to 64 by default.
11. What four things do we need to tell fastai to create DataLoaders?
- The data you are working with
- How to get the list of items
- How to label these items
- How to create a validation set
12. What does the splitter parameter to DataBlock do?
The splitter spilts the data into a training set and a validation set.
13. How do we ensure a random split always gives the same validation set?
14. What letters are often used to signify the independent and dependent variables?
Independent is denoted by x and dependent by y.
15. What's the difference between the crop, pad, and squish resize approaches? When might you choose one over the others?
- Crop: Just crops the image and takes the center part of it. This means that you might lose some of the data. YOu can use this when only the center parts of the images matter.
- Pad: If you don't want to lose any data you can pad the images, which is like add more pixels around the image to make it the size you want. However that added portion is completely unnecessary and a total waste of computation. You can use this when you don't want to lose any imformation stored in the image nor do you want to contort these images by squishing and stretching.
- Squish: This squishes your images by stretching or squeezing them in the desired size. This also has a downside that now all of your images are contorted. Yo may want to use it when you want the entire image, and don't want to lose on unecessary computation by padding these images.
16. What is data augmentation? Why is it needed?
Data augmentation is basically creating random variations of our training data set, so that images appear different like different lighting, warping the perspectives, rotating, but not so different so as to change the meaning of the image. This helps the model understand how objects of interest are represented and generalizing them.
17. What is the difference between item_tfms and batch_tfms?
item_tfms is item transform which transforms(stuff like resizing images) image by image and batch_tfms is used o transform whole batches which are transferred to the GPU which results in the processing being much faster.
18. What is a confusion matrix?
A confusion matrix is a n^2 matrix that shows you what were the predictions of the pictures you passed into the model.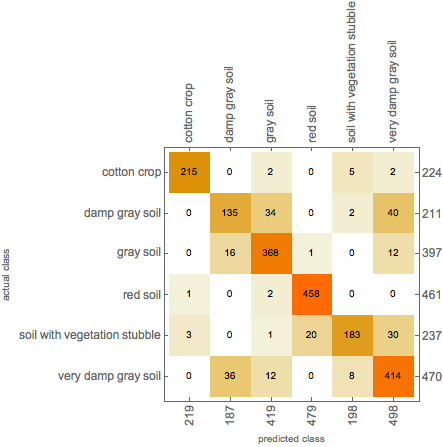 Here the diagonal shows how many of the images were actually predicted correctly.
Here the diagonal shows how many of the images were actually predicted correctly.
19. What does export save?
20. What is it called when we use a model for getting predictions, instead of training?
21. What are IPython widgets?
Create GUIs in Jupyter Notebooks itself, so you can prototype and build applications.
22. When might you want to use CPU for deployment? When might GPU be better?
You might want to use a CPU when you don's have as much processing to do, maybe you are working with simple image data and need to deploy your work for cheap. Whereas you might want to use a GPU where your dealing with video data which would take a lot of processing time on a general CPU. GPUs are best for doing identical work in parallel. If you will be analyzing single pieces of data at a time (like a single image or single sentence), then CPUs may be more cost effective instead, especially with more market competition for CPU servers versus GPU servers. GPUs could be used if you collect user responses into a batch at a time, and perform inference on the batch. This may require the user to wait for model predictions. Additionally, there are many other complexities when it comes to GPU inference, like memory management and queuing of the batches.
23. What are the downsides of deploying your app to a server, instead of to a client (or edge) device such as a phone or PC?
Maybe this question needs a little reframing. Deploying your app to an edge device leads to a lot of privacy concerns, latency, version control problems, load balancing issues, scalibility issues and it is just a mess. Deploying it to a server is much more efficient and ergonomical. YOu have more control over the environment and none of those issues are found here.
24. What are three examples of problems that could occur when rolling out a bear warning system in practice?
The bear classfication model will work poorly in real life conditions, where we would be dealing with video instead of images, the input of the cameras might be of very low resolution, nighttime images, we have to ensure there is no processing latency, bears might not be properly positioned in from of these cameras.
25. What is "out-of-domain data"?
The data you've trained on is different from the data your model shall see during production. Even having a diverse team can help coming up with a wider dataset, but there isn't any technical solution to this problem.
26. What is "domain shift"?
Domain shift is when you start out with data that might be in your domain, but then over time the type of data changes a lot and then again your model isn't abe to adapt to it. An easy solution is using a transfer learning on a daily basis so that your model can gradually adapt to the new data. Maybe then even fine tuning it to make it better would work out.
Biased data
All data is biased. Timnit Gebru suggested in a paper that we define how this data is collected, so that in the longer run biased results don't backfire on us and we understand the limitations of that specific collected dataset.
27. What are the three steps in the deployment process?
The three steps in the deployment process are:
- Manual process: Run the model in parallel and have humans check all of the predictions.
- Limited scope deployment: Have it run in a environment limited by either time or space, this should be done under human supervision.
- Gradual expansion: There should be good reporting systems in place, and you should always consider what could go wrong.
28. What is a p value?
Often times we take a dataset so small that we start seeing relationships betweeen the inputs coincidently, that is why to verify them we use a p value. We start off with a null hypothesis which says there is no relationship then we collect independent and dependent variables. After this we calculate the percentage of the time we would see that relationship. A p-value is the probability of an observed result assuming the null hypothesis is true. But it is not always that p values are to be trusted extra reading: American Statistical Association on p-values and Frank Harrell's Null Hypothesis Significance Testing Never Worked
29. What is a prior?
Further Research
1. Consider how the Drivetrain Approach maps to a project or problem you're interested in.
2. When might it be best to avoid certain types of data augmentation?
3. For a project you're interested in applying deep learning to, consider the thought experiment "What would happen if it went really, really well?"
4. Start a blog, and write your first blog post. For instance, write about what you think deep learning might be useful for in a domain you're interested in.
Huh, a blog you say... Yeah, I'll think about it.